Research
Our overarching goal is to create novel software systems to simplify the programming complexity of heterogeneous computing resources. Our systems target performance-critical applications, such as computer-aided design, machine learning, and quantum computing. We have released several open-source software projects (e.g., Taskflow, OpenTimer) that are being used by many industrial and academic projects. Our research is framed by the following themes:
- Theme #1: Heterogeneous Programming Environments
- Theme #2: Electronic Design Automation
- Theme #3: Quantum Computing
- Theme #4: Machine Learning Systems
Theme 1: Heterogeneous Programming Environments
Research Question: How can we make it easier for researchers and developers to write parallel and heterogeneous programs with high performance and simultaneous high productivity?
Modern scientific computing relies on a heterogeneous mix of computational patterns, domain algorithms, and specialized hardware to achieve key scientific milestones that go beyond traditional capabilities. However, programming these applications often requires complex expert-level tools and a deep understanding of parallel decomposition methodologies. A suitable software environment that can streamline the complexity of programming large parallel and heterogeneous systems is therefore very crucial to facilitate transformational scientific discoveries. Our research investigates new programming environments to assist researchers and developers to tackle the implementation complexities of high-performance parallel and heterogeneous programs.
![]()
Taskflow: A General-purpose Parallel and Heterogeneous Task Programming System
Taskflow helps C++ developers quickly write parallel and heterogeneous programs with high performance and simultaneous high productivity.
Taskflow in 5 Minutes
Taskflow in 15 Minutes
![]()
Taro: Task Graph-based Asynchronous Programming System using C++ Coroutine
Taro is an asynchronous task graph programming system that allows you to write coroutines in a task graph while abstracting away complex coroutine management.
![]()
DtCraft: A Distributed Programming System using Data-parallel Streams
DtCraft helps developers streamline the building of high-performance distributed applications using data-parallel streams on a machine cluster.
Theme 2: Electronic Design Automation
Research Question: How can we leverage emerging heterogeneous parallelism to speed up electronic design automation (EDA) algorithms and achieve order-of-magnitude performance breakthrough?
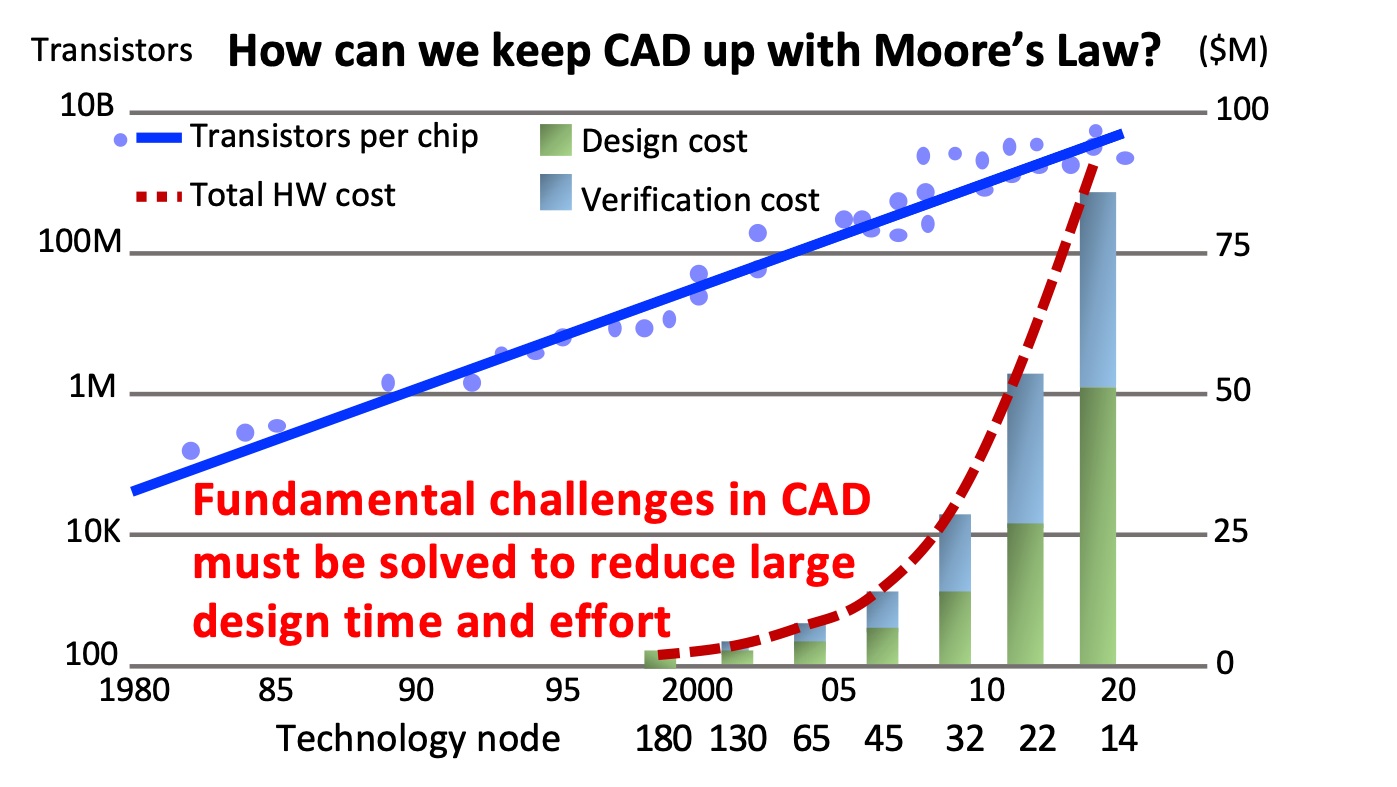
The ever-increasing design complexity in very-large-scale integration (VLSI) implementation has far exceeded what many existing electronic design automation (EDA) tools can scale with reasonable design time and effort. A key fundamental challenge is that EDA must incorporate new parallel paradigms comprising manycore central processing units (CPUs) and graphics processing units (GPUs) to achieve transformational performance and productivity milestones. However, this goal is impossible to achieve without a novel computing system to tackle the implementation complexities of parallelizing EDA, such as irregular task parallelism, large CPU-GPU dependent tasks, dynamic control flow, and distributed computing, which cannot be expressed and executed efficiently with mainstream parallel computing systems. Our research investigates new computing methods to advance the current state-of-the-art by assisting everyone to efficiently tackle the challenges of designing, implementing, and deploying parallel EDA algorithms on heterogeneous nodes.
![]()
OpenTimer: A High-performance Timing Analysis Tool for VLSI Systems
OpenTimer helps electronic design automation tool researchers and developers quickly analyze the timing of large circuit designs.
![]()
RTLflow: A GPU Acceleration Flow for RTL Simulation with Stimulus Batches
RTLflow helps circuit designers quickly simulate RTL designs using automatically generated C++ and CUDA code on a high-throughput GPU platform.
Theme 3: Quantum Computing
Research Question: How can we create fast and reliable software for researchers and developers to understand quantum operations and design reliable quantum computers?
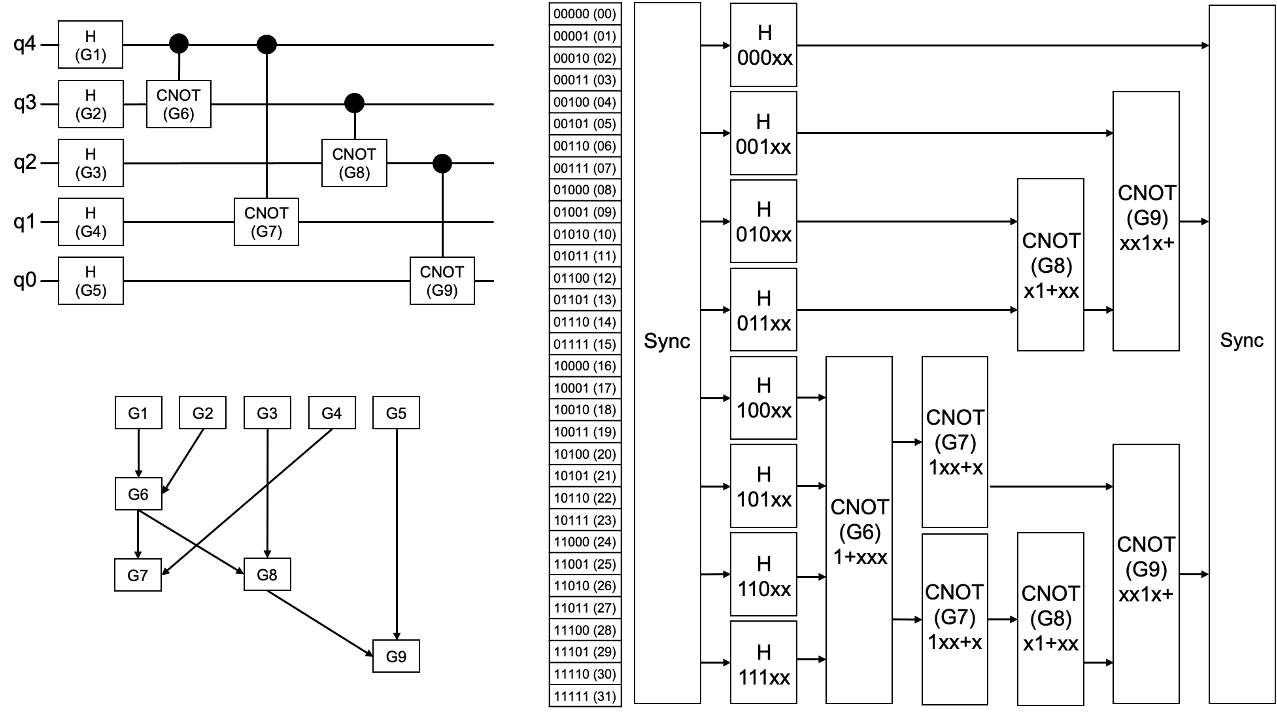
Quantum computing (QC) is a promising computing paradigm for tackling certain types of problems that are classically intractable, such as cryptography, chemistry simulation, finance, and combinatorial optimization. Among various QC applications, classical software support for quantum circuit analysis and synthesis is essential for researchers to understand quantum algorithms and optimize quantum circuits. However, building such software is extremely challenging because it demands large computation and memory to evaluate quantum operations. For example, simulating an n-qubit quantum circuits requires an exponential size of vector to store 2^n amplitudes, as a result of superposition. Our research investigates new algorithms for quantum circuit simulation and optimization by leveraging the power of classical high-performance computing techniques.

BQSim: GPU-accelerated Batch Quantum Circuit Simulation
BQSim helps quantum computing researchers and developers quickly simulate how quantum circuits work using the power of GPU.
![]()
FlatDD: Quantum Circuit Simulation using Decision Diagram and Flat Array
FlatDD helps quantum computing researchers and developers quickly simulate the functionality of quantum circuits using efficient CPU-parallel algorithms.
Theme 4: Machine Learning Systems
Research Question: How can we accelerate machine learning kernels in large-scale inference and training workloads using modern heterogeneous computing techniques?
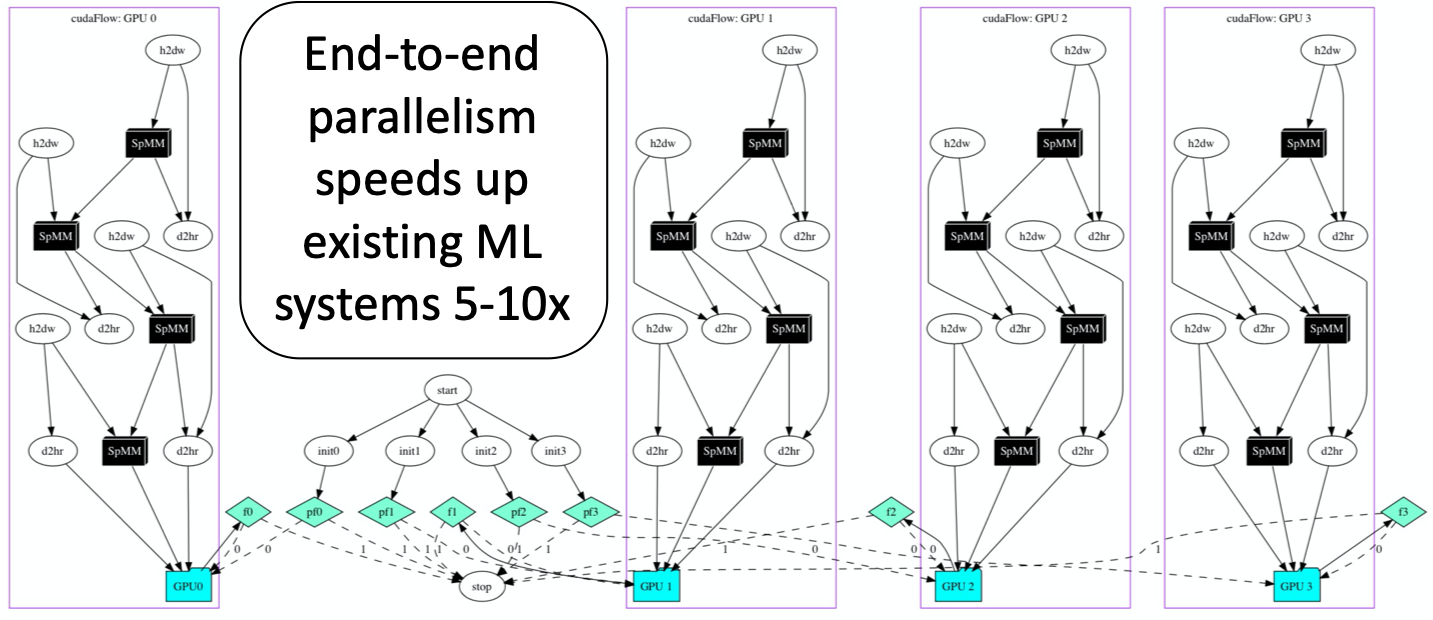
Machine learning has become centric to a wide range of today’s applications, such as autonomous driving, recommendation systems, and natural language processing. Machine learning algorithms are based on deep neural networks (DNN), which commonly have millions or billions of parameters to compute. Due to the unique performance characteristics, graphics processing units (GPUs) are increasingly used for machine learning applications and can dramatically accelerate neural network training and inference. Modern GPUs are fast and are equipped with new programming models and scheduling runtimes that can bring significant yet largely untapped performance benefits to many machine learning applications. For example, our research has shown that by leveraging the new GPU task graph model in CUDA to describe end-to-end parallelism, we can achieve 5–10 times speed-up over existing systems. Our research investigates novel parallel algorithms and frameworks to accelerate machine learning system kernels with order-of-magnitude performance breakthrough.
![]()
SNIG: Large Sparse Neural Network Inference using Task Graph Parallelism
SNIG is the Champion-Award inference engine of the 2020 IEEE/MIT/Amazon HPEC Graph Challenge for Large Sparse Neural Network.
Sponsors
We are grateful for funding from University of Utah, University of Wisconsin, National Science Foudation, Defense Advanced Research Projects Agency, NumFocus, Nvidia, and Intel.
![]()


![]()


![]()
![]()